前情提要
大约1年半前,我在某咖啡项目上做一些后端业务,数据库是用的couchbase。(谁选的,为啥选的,一概不知。
在使用过程中发现,并发高了之后,Couchbase在平均响应时间/95%时间依旧非常美观的情况下,后端API反倒会夹杂着一些请求超时,并发越高越明显。
这个问题一直没有被解决,最近机缘巧合,开始尝试解决这个问题。
先通过非Java版本(就是Go)的Couchbase SDK做同样的测试,得出问题应该是出在Client端,而非Server端。1
根据Couchbase SDK的源码梳理了一下整个查询的流程。
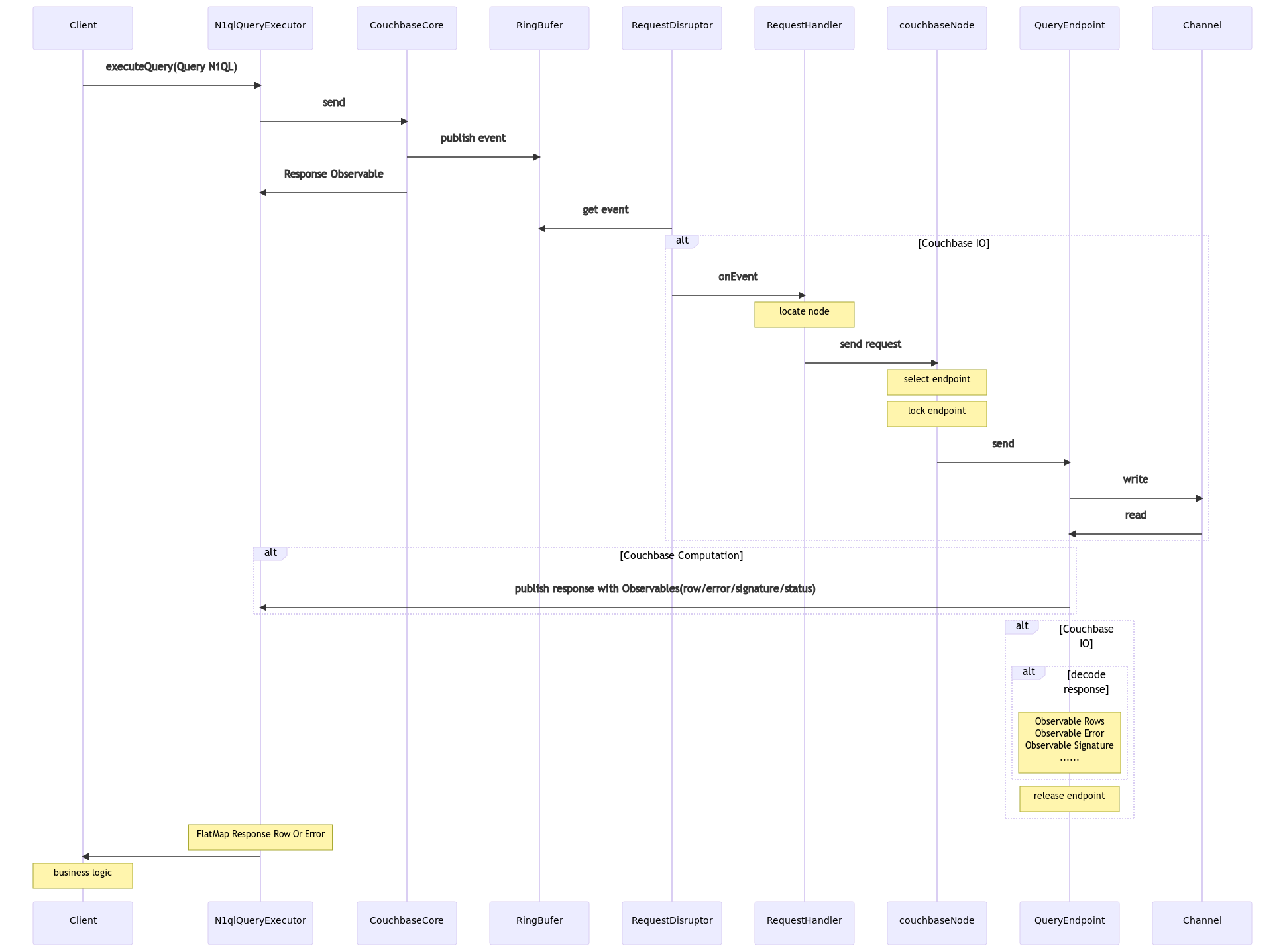
尝试回答之前的问题
-
为什么会超时?
在couchbaseNode那一块逻辑的时候,没有足够的Endpoint,会直接进入重试,重试直至超时。
-
怎么解决Endpoint不够的问题?
最直接的办法就是调大Endpoint的连接数,Spring Data默认1,官方推荐6-10,在实际项目中甚至都被调到30-50了。数值调大之后确实缓解了出错情况。
-
为什么Endpoint调这么大了,依然会出错?
因为没来得及释放Endpoint,负责释放Endpoint的IO线程被Block住了。后面的业务逻辑实际上是在IO线程上执行。
-
图上publish response给客户端,是在Computation线程池,为什么会出现IO线程的问题?
按照设计,业务确实应该都是跑在Computation线程池上(或后期切换到其他线程),IO线程对SDK的使用者来说,应该是不可见的。
问题出在这个代码块:
//org/springframework/data/couchbase/core/RxJavaCouchbaseTemplate.java:392 @Override public <T>Observable<T> findByN1QL(N1qlQuery query, Class<T> entityClass) { return queryN1QL(query) .flatMap(asyncN1qlQueryResult -> asyncN1qlQueryResult.errors() .flatMap(error -> Observable.error(new CouchbaseQueryExecutionException("Unable to execute n1ql query due to error:" + error.toString()))) .switchIfEmpty(asyncN1qlQueryResult.rows())) .map(row -> { JsonObject json = ((AsyncN1qlQueryRow)row).value(); String id = json.getString(TemplateUtils.SELECT_ID); Long cas = json.getLong(TemplateUtils.SELECT_CAS); if (id == null || cas == null) { throw new CouchbaseQueryExecutionException("Unable to retrieve enough metadata for N1QL to entity mapping, " + "have you selected " + TemplateUtils.SELECT_ID + " and " + TemplateUtils.SELECT_CAS + "?"); } json = json.removeKey(TemplateUtils.SELECT_ID).removeKey(TemplateUtils.SELECT_CAS); RawJsonDocument entityDoc = RawJsonDocument.create(id, json.toString(), cas); T decoded = mapToEntity(id, entityDoc, entityClass); return decoded; }) .doOnError(throwable -> Observable.error(new CouchbaseQueryExecutionException("Unable to execute n1ql query", throwable))); }在
queryN1QL(query)之后的业务都是跑在Computation上的,但是flatMap可能会带来线程重新切换回IO的问题。因为asyncN1qlQueryResult.rows()本身是一个跑在IO线程上的热源。在QueryEndpoint拿到response的时候,会把publish和decode同时进行,publish会放在
Computation去做,decode依然会放到IO。当代码执行到这一块的时候,如果decode完成,就会继续在Computation进行执行。一切ok。
如果decode没有执行完成,后面的一系列操作,包括业务逻辑,就都会在IO上进行操作,在业务操作完成之前,IO线程都无法释放Endpoint。
如何改进?
- 调换decode response和release endpoint的顺序,理论上拿到返回,就不应该再占用连接,就算后面decode导致io线程泄露,也不会影响endpoint释放。
- 在
flatMap拿到rows的时候,强制用observeOn来切换成其他线程。
设计一个复现场景
//默认spring data couchbase endpoint=1
//当couchbase返回的数据包比较大的时候,最后一条Query失败的概率非常高,如果把limit改成1,就几乎不会失败了。
public void getLargeDataAndBlock() {
RestTemplate restTemplate = new RestTemplate();
rxJavaCouchbaseTemplate.findByN1QL(N1qlQuery.simple("SELECT META(`demo`).id AS _ID, META(`demo`).cas AS _CAS, `demo`.* FROM `demo` where `_class` = \\"com.example.cbts.TestData\\" limit 100"), TestData.class)
.take(1)
.doOnNext(it -> {
logger.info("hello {}", Thread.currentThread().getName());
ResponseEntity<String> forEntity = restTemplate.getForEntity("<http://httpbin.org/delay/20>", String.class);
})
.subscribe();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
N1qlQueryResult n1qlQueryRows = couchbaseTemplate.queryN1QL(N1qlQuery.simple("select * from `demo` where meta().id=\\"1\\""));
}
然而
按道理说,写到这里应该是可以装一波了,然而,经过测试,发现上面的一些改动压根没办法解决空负载压测的报错。(也许能解决真实业务场景中的错误情况
因为整个webflux+couchbase的模型就是一个不带背压的生产消费模型,每个endpoint每次处理请求的时间基本是固定的。
(单位时间/单个endpoint处理单条请求时间)*endpoint数量
这就是能正常处理的tps,但是这个tps和webflux的tps是脱节的,couchbase client已经满负载了,webflux还在接受请求放入队列,最终结果就是超时报错。
这样的结果确实是有点反直觉的,看数据库,发现响应时间都挺好看的。看web framework,所有请求都能接受。但是API却有大量的报错,给人一种数据库牛逼,WEB框架牛逼,数据库客户端拖后腿的感觉。
要打破这一幻象,只需要把endpoint调到足够大之后,Couchbase 服务端就会开始出现“响应时间开始明显下降”,整体的有效TPS不升反降。整个表现就符合心目中数据库不行的样子了。
所以最终的一系列结论如下:
- Endpoint的设置是为了保护Couchbase Server,让其性能跑在一个甜点区。数据库性能下降和客户端排队二选一。
- Couchbase跑N1QL就是不行。
-
Go测试的坑:Go没有endpoint连接数的概念,有点那种来多少就连多少的味道,在Couchbase没有达到极限之前,确实不会报错,TPS也会更好看。但一旦压测力度上去了,Go SDK的数据惨不忍睹。 ↩︎